WebUIで動画生成!!!【text-to-video】



こんにちは、画像生成AIでひたすら猫のイラストを生成している じょじお(@jojio‗illust)です。
Stable DeffusionのWebUI上で利用できる、テキストから動画を生成できるツールが話題になっていたので試してみました。

▲AI画像の大量ファイルをプロンプトと一緒に簡単に整理する方法はこちら。

▲素材に関連する英単語100個以上まとめました。

▲すべてのプロンプト関連記事はこちらにまとめています。

▲Midjourneyユーザー向け。専用Discordサーバーを作って画像生成作業を効率化する方法。
「modelscope」text2video
ModelScopeというテキストから動画を生成できるツールがTwitterで話題になっていました。
上のような動画をテキスト入力だけで簡単に作れるツールのようです。この動画は、実際にテキストだけで私が作った動画ですw
そして先日、Stable Deffusion WebUI上で利用できる拡張機能をどなたかが作ってくれたようなのでそちらを試してみました。
参考
「modelscope」text2videoのインストール方法
前提条件
- Stable diffusionをWebUIをインストール済みであること
- PCのディスクの空き容量が10GB程度必要。
WebUIをインストールしていない方は下記にインストール方法を紹介しています。

ModelScope拡張機能のインストール
 じょじお
じょじお早速インストールしてみます。
インストールはWebUI上から行います。
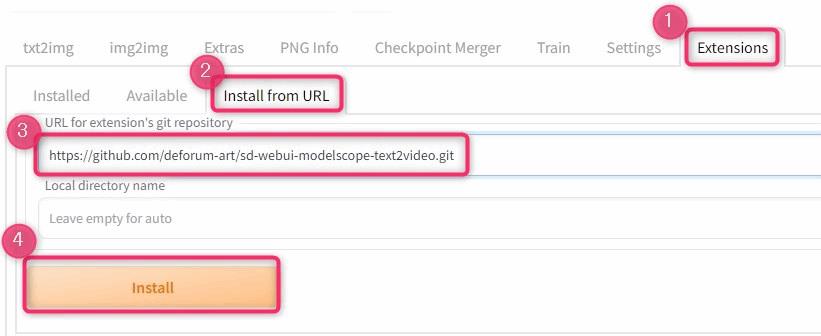
▲WebUIを起動したら、「Extensions」タブをクリックして、「Install from URL」をクリック。
下記のURLを入力して、Installをクリックします。
拡張機能のリポジトリURL
https://github.com/deforum-art/sd-webui-modelscope-text2video.git
インストールは数秒で終わるはずです。

▲インストールしたらWebUIをリロードします。リロードはWebUIの一番の下の「Reload UI」から。

▲リロードすると「ModelScope text2video」というタブが追加されています。
じょじおモデルが必要なため、まだ利用することはできません。モデルファイルが必要なのでダウンロードしにいきましょう。
モデルのダウンロード
ModelScope text2videoの実行のために下記の4つの必要なファイルがあります。これらは自分で準備しなければなりません。これを準備していきます。
- (あなたWebUIをインストールした場所)\stable-diffusion-webui\outputs\img2img-images\text2video-modelscope\t2v
- VQGAN_autoencoder.pth
- configuration.json
- open_clip_pytorch_model.bin
- text2video_pytorch_model.pth
下記のHugging FaceのURLへアクセスします。
modelscope-damo-text-to-video-synthesis
https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis/tree/main
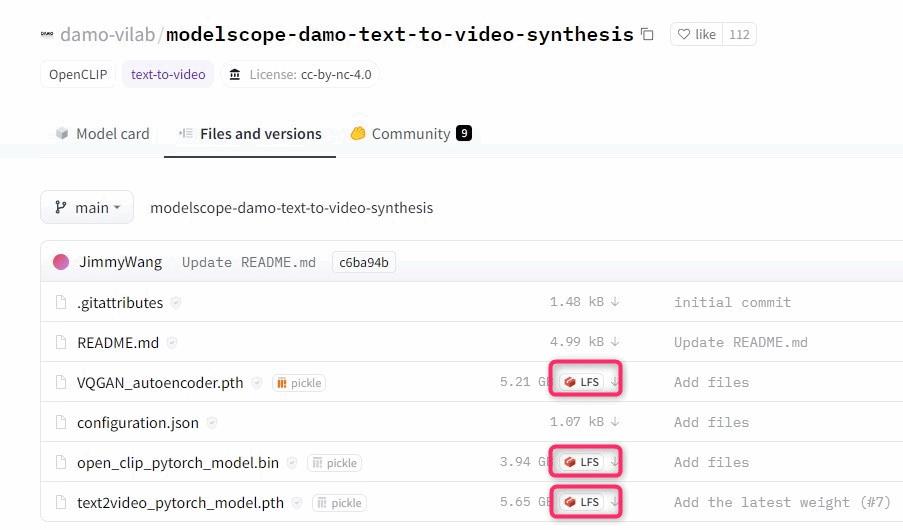
▲まずは上の図の3つのファイルをダウンロードして下記の場所に保存します。
(あなたWebUIをインストールした場所)\stable-diffusion-webui\models\ModelScope\t2v▲ModelScopeフォルダと、t2vフォルダは、自分で新たに作成する必要があります。
設定ファイルの設置(configuration.json)
最後にモデルを設置した場所に設定ファイルを作成します。
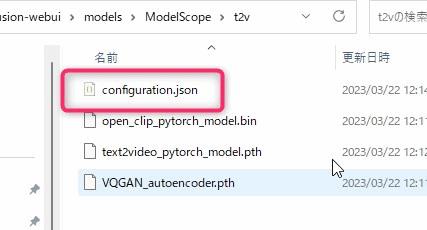
▲stable-diffusion-webui\models\ModelScope\t2vの中に空のテキストファイルを作成して「configuration.json」という名前に変更します。拡張子を変更することでテキストファイルをJSONファイルに変更します。
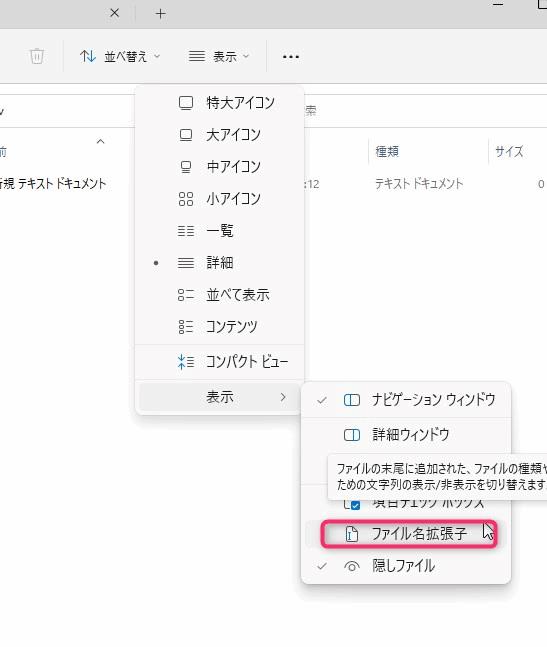
PCの設定によっては、ファイルの拡張子を変更できません。そういう時は、Windows11であれば「エクスプローラー>表示>表示>ファイル名拡張子のチェックをオン」の手順で拡張子を表示できます。
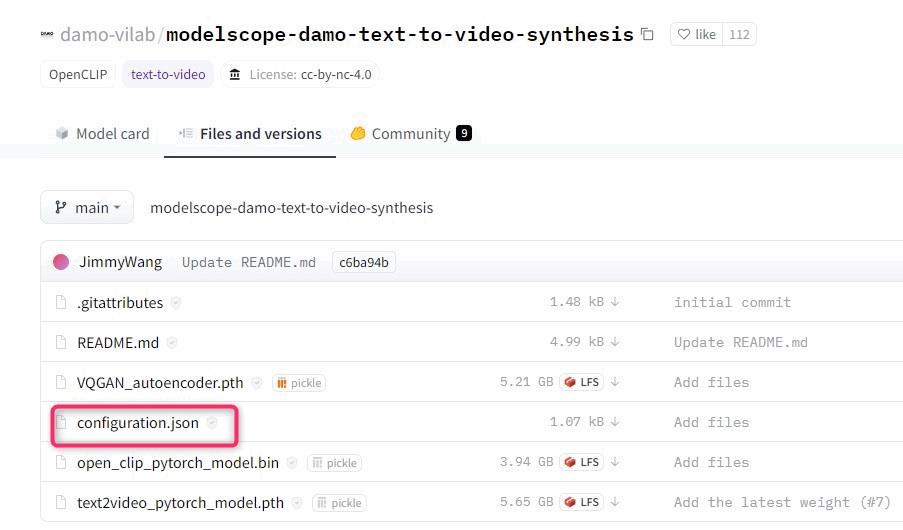
▲Hugging Faceの「Configuration.json」をクリックして開きます。
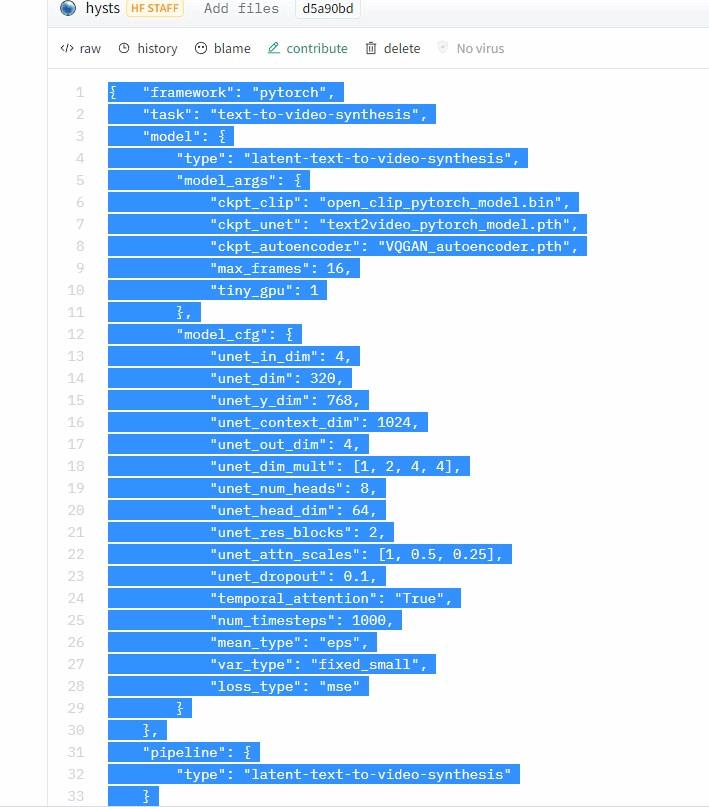
▲Configuration.jsonの中身をコピーします。コピーしたら、先ほど作成した空っぽのConfiguration.jsonに張り付けて保存して閉じます。
以上でインストールは終わりです。
最終的に下記の4つのファイルを格納しました。
「modelscope」text2videoのWebUIの操作方法
じょじお早速使ってみましょう!
動画生成は「Modelscope text2video」タブから行います。
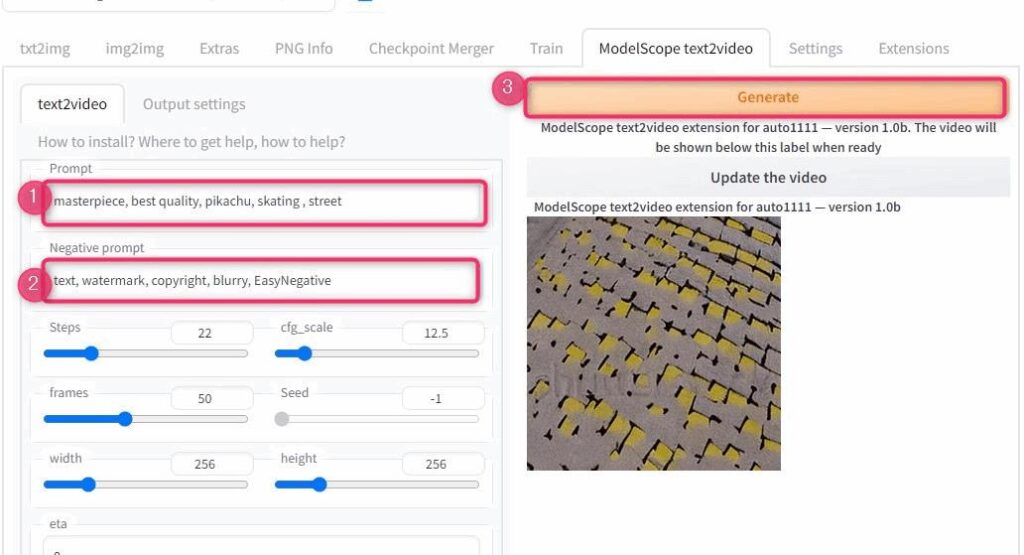
▲Modelscope text2videoタブに移動したら、画像生成と同じように、プロンプトとネガティブプロンプトを入力して「Generate」ボタンを押すだけです。
今回使用したプロンプトはこちら。
masterpiece, best quality, graffiti pikachu, skating , streettext, watermark, copyright, blurry, EasyNegative動画が生成されているかどうかはWebUI上ではわからないので、常駐しているコマンドプロンプトのログを見ましょう。
 じょじお
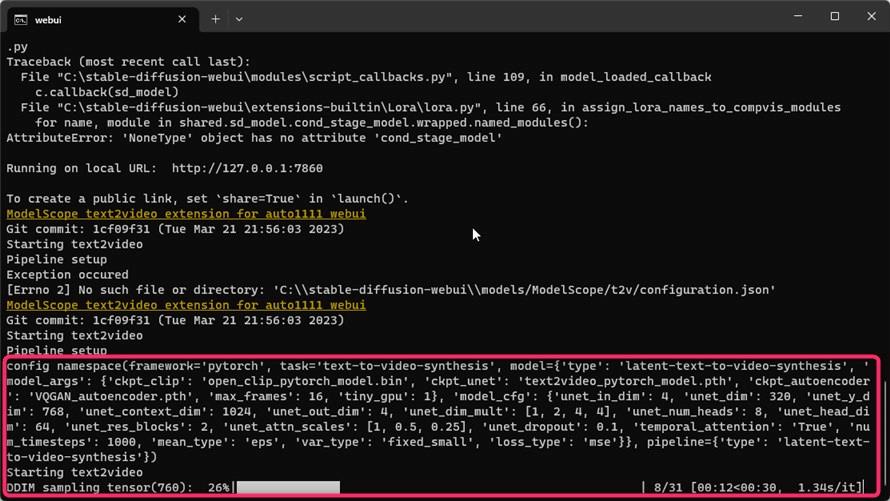
じょじお初回実行時だけ、必要なファイルのセットアップのために少しだけ時間がかかるみたいです。
 じょじお
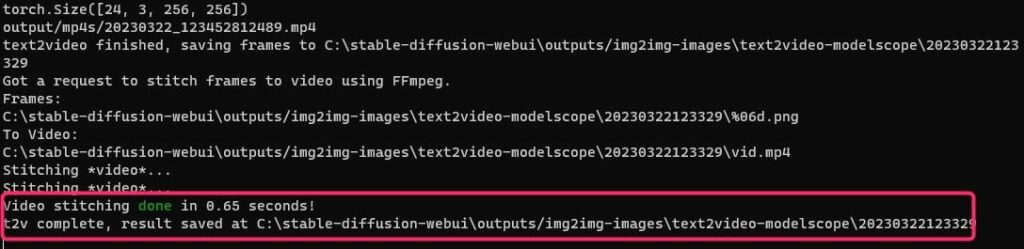
じょじおWebUI上で実行完了が確認できません(バグかな)
コマンドプロンプトを確認し、上の図のように緑の文字で「Done」と表示されれば生成完了です。
 じょじお
じょじおファイルは上の図の「Update the video」ボタンをおせばWebUI上で動画を見ることができます。
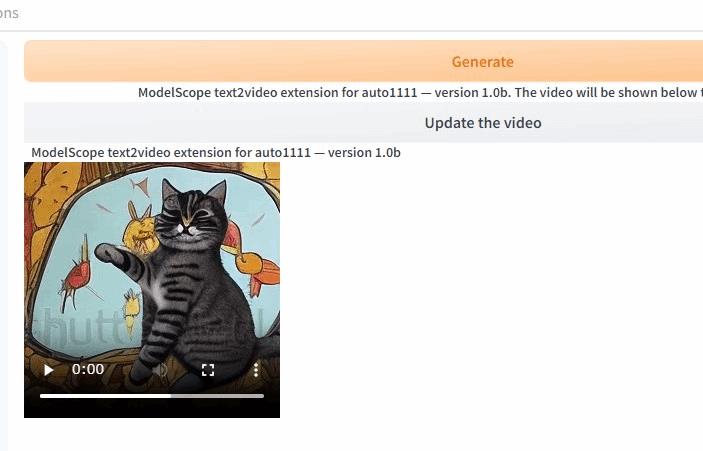
作成した動画の紹介
じょじおいくつか作ってみたので紹介します。
パラメータとかエラーとか。
パラメータについて
基本的にはText-to-imageとパラメータは同じようです。Text-to-Videoならではの設定は、frames, fpsなどがあります。
- FPS:数値を上げるほど滑らかになる。デフォルト15
- フレーム:大きくすると生成時間が長くなります。
保存場所
生成した動画は下記のフォルダに保存されます。
(あなたがWebUIをインストールした場所)\stable-diffusion-webui\outputs\img2img-images\text2video-modelscopeエラー:No such file or directory
下記のエラーが出る場合は、「configuration.json」が正しく認識されていません。
Git commit: 1cf09f31 (Tue Mar 21 21:56:03 2023)
Starting text2video
Pipeline setup
Exception occured
[Errno 2] No such file or directory: ‘C:\stable-diffusion-webui\models/ModelScope/t2v/configuration.json’
ModelScope text2video extension for auto1111 webui
下記を確認しましょう。
- jsonファイルがテキストファイルの拡張子になっていないか
- jsonのファイル名が間違っていないか
- 保存場所が間違っていないか
- フォルダ名が間違っていないか。
エラー:CUDA out of memory
フレーム数をマックスにしたら下記のエラーが出た。
CUDA out of memory. Tried to allocate 6.25 GiB (GPU 0; 12.00 GiB total capacity; 9.55 GiB already allocated; 308.06 MiB free; 9.70 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
エラー
VRAMが足りないらしい。フレーム数を下げるか、「max_split_size_mb」の設定を有効にすれば回避できる可能性もあるようです。
私はこの機能に関しては試していませんが、以前、「max_split_size_mb」の設定を変更したことがあります。変更方法はその記事をご覧ください。

shutterstockという透かしが入る。
ネガティブプロンプトで、テキストを消す対策をしても、shutterstockの透かしが必ず入ってしまいました。
仕様かもしれません。わかり次第追記します。
使ってみた感想。
私のPC(RTX3060 VRAM16GB)では、256×256サイズの2秒の動画(フレーム数40)を生成するのに、2分30秒くらいかかります。もう少し早く生成できたらうれしいなぁと思っちゃいました。
また、大きいサイズの動画を生成しようとすると途中で止まってしまいます。画像生成よりもPCスペックが求められそうです。
ModelScopeの応用的な使い方として、生成した動画をimage-to-imageして、自分好みのスタイルに変化させている方がいました。
Modelscope提供のモデルは、今現在流行している画像生成用2次元イラスト専用モデルと比較するとクオリティが劣ります。
i2iできたら、利用の幅も増えそうです。こちらも今度試してみたら記事にて紹介したいと思います。
まとめ
以上、Text-to-Videoについて紹介しました!
じょじお最後まで読んでくださってありがとうございます!
この記事がお役に立てましたら、シェアボタンからシェアしていただけたら嬉しいです!

【おすすめUdemy講座】Midjourney始め方から応用まで網羅!【完全版】
【おすすめUdemy講座】ジェネレーティブAI(生成AI)入門【ChatGPT/Midjourney】 -プロンプトエンジニアリングが開く未来-
コメント
コメント一覧 (2件)
こんにちは!
colabでやったらクラッシュしちゃいました。
やっぱりスペックの高いPCじゃないとだめなんですかね!
レスおそくなって、すいません・・・。
結構スペック必要と思います。わたしも大きい動画作ろうすると止まっちゃいます。