【画像生成AI】無料で誰でもかんたんにカスタムモデルを作成する方法。



こんにちは、画像生成AIのプロンプトを研究している じょじお(@jojio‗illust)です。
この記事は、無料で使える画像生成AIサービス「Leonardo.ai」でオリジナルのカスタムモデルを作成する方法を紹介します。
「自分だけのカスタムモデルを作成したいけど、ハイスペックPCを持っていないし、課金もしたくないよぉ!」という方でも、Leonardo.aiなら、かんたんにカスタムモデルを作成することが可能です。
モデルファインチューニングに興味がある方は、ぜひ、この記事をご覧ください。
 じょじお
じょじおわたしは、今回Midjourneyの画像8枚を使ってカスタムモデルを作ってみました!

▲AI画像の大量ファイルをプロンプトと一緒に簡単に整理する方法はこちら。
Stable Diffusionのプロンプトエンジニアリングの基本について理解したい方には、初心者向けのプロンプトガイドを作りましたのでそちらを見てください!

無料でカスタムモデルを作成できるLeonardo.aiとは?
Leonardo.Aiは無料で使える画像生成AIを使って画像生成ができるWebサービスです。
無料で使える画像生成AIにはDall-E2や、BingAI、Fireflyなど、多数ありますが、Leonardo.aiは他のAIツールと比較してできる事が多い点と、生成できる画像のクオリティの高さからとても注目されています。
じょじお無料ツールを探している人におすすめするならLeonardo.aiです。
Leonardo.ai は無料ユーザーでもファインチューニングができる?
Leonardo.ai のうれしいところは、無料ユーザーでも月に2回までモデルのファインチューニングができる点です。
ファインチューニングは、学習済みのモデルに対して、新たなデータセットを使って微調整を行うことです。
Leonardo.ai では、Stable Diffusion ver1.5あるいはStable Diffusion ver2.1に、ファインチューニングを行うことで自分だけのカスタムモデルを作成できます。
Leonardo.aiの使い方は?
Leonardo.aiは下記からサインアップを行います。
筆者はすでにアカウント作成済みのためわからないのですが、もしかしたら、アーリーアクセスリストに登録しないと使用できないかもしれません。その場合は下記リンクから、メールアドレスの登録とLeonardo.aiのDiscordサーバーへ登録をしてください。
Leonardo.ai でカスタムモデルを作成するためのステップ
Leonardo.ai でカスタムモデルを作成するには次の3つのステップで作業を行います。
- トレインデータ(画像ファイル5~15枚程度)の準備
- ファインチューニング(トレーニング)
- カスタムモデル完成+AI画像生成
じょじお15枚程度の画像でファインチューニングできるのでお手軽ですね。
 わんこ
わんこパラメータ設定も難しい要素はないので安心してください。
1.トレインデータの準備(画像ファイルの準備)
じょじおまずはトレインデータ(画像ファイル)を用意しましょう!!!!
トレインデータとして適切なのは下記の画像です。
推奨の画像サイズは?
データセットのサイズについては、一般的には画像ファイルのサイズが大きすぎると、トレーニングにかかる時間が長くなるため、必要最小限のサイズに抑えることが推奨されます。画像ファイルのサイズは、通常、512×512ピクセル程度が推奨されますが、トレーニングするモデルやデータセットの内容によっては、異なるサイズが必要な場合があります。
ベースのモデルにStable Diffusion ver2.1を選択する場合は、768×768が推奨されます。
じょじお現在、Leonardo.ai ではSD1.5を推奨しているようです。このため特に理由がない場合は512×512のサイズで統一するのがよさそうです。

推奨の画像の枚数は?
Leonardo.Aiでは、トレーニングに使用する画像ファイルの数は8〜15枚が推奨されますが、種類やデータセットの内容によっては、より多くの画像が必要な場合があります。
また、最小で5枚、最大で30枚まで使用できます。
トレインデータの選び方のコツ
トレインデータは下記に注意しましょう。
トレインデータの品質
トレインデータに用いる画像ファイルは品質に注意しましょう。小さいサイズの画像を引き延ばしたような、劣化した荒い画像を学習させた場合、AIから生成される画像の品質も低下する可能性があります。可能であれば綺麗な画像を使いましょう。
トレインデータの多様性
トレインデータに用いる画像ファイルは、多様性に富んだファイルを用意しましょう。
これは、重要なものは必ず画像に含める必要がありますが、それ以外の要素は様々なバリエーションがいいということです。
理由は、似たような画像ばかり学習させると、似たような画像しか生成できないからです。
例として、日本のタレント「タモリさん」を学習させる場合を考えてみます。
タモリさんの重要な要素を考えた時、おそらくタモリさんを知る誰もが「サングラス」と「オールバックのヘアースタイル」と答えるのではないでしょうか。タモリさんの場合、この2つをすべてのトレインデータに含める方が良いでしょう。
一方、それ以外の要素は、あえてバリエーションを変えます。様々な服装、様々な背景に映るタモリさんの画像を用意するのがいいでしょう。
これによってタモリさんの特徴を学習しつつ、バリエーションに富んだタモリさんを生成できるようになります。
もちろん、「私はスーツ姿のタモリさんだけを生成したいんだ!」という人は、スーツ姿に固定した画像ファイルを用意するのがベターです。
画像の一括リサイズはEagleが便利です。
画像の一括リサイズは、Eagleがとても便利です。方法は下記の記事で紹介していますので参考になさってください。
▲Eagleで一括リサイズする方法はこちら
▲EagleはAI画像の管理におすすめのソフトウェアです。クリエーターさんには絶対に一度触ってほしい!
\ 30日間 無料で使える! /
今回私が使用するデータ
じょじお私は今回Midjourneyで生成した下図の「黒い太ったネコ」さんの画像を使いましたー!
 わんこ
わんこ似たような画像ばかりだね・・・?
じょじおそうですね。確かに本来はもう少し背景にバリエーションを持たせべきです。まぁ悪い例ということで。
(今月分のクレジットを使ってしまって修正できない)

▲Midjourneyの使い方はこちら
じょじお画像ファイルが準備できたら、次の項にすすみましょう!
2.モデルの作成
じょじお準備した画像をLeonardo.ai にアップロードしましょう!
Leonardo.ai では画像のセットのことをデータセットと呼ぶよ。
①データセットのアップロード
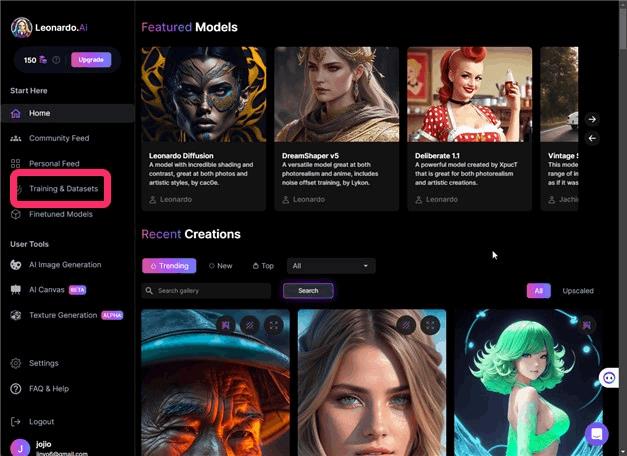
▲Training & Datasetsをクリックします。
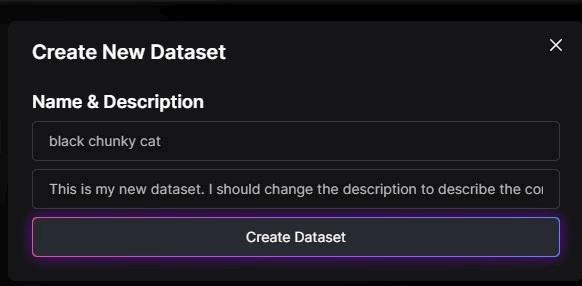
▲Datasetに名前を付けます。
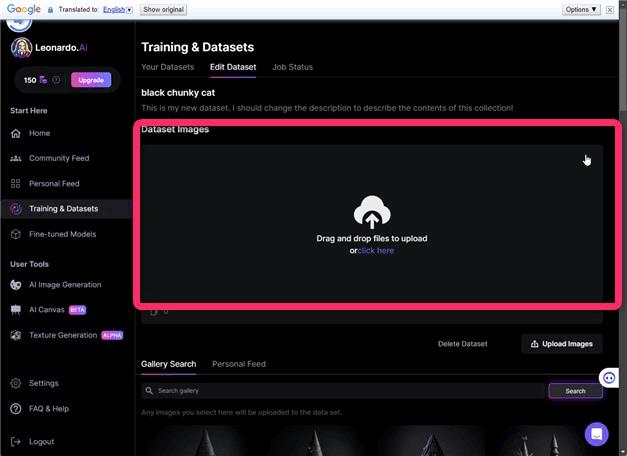
▲画像をアップロードします。
②モデル学習(Train model)
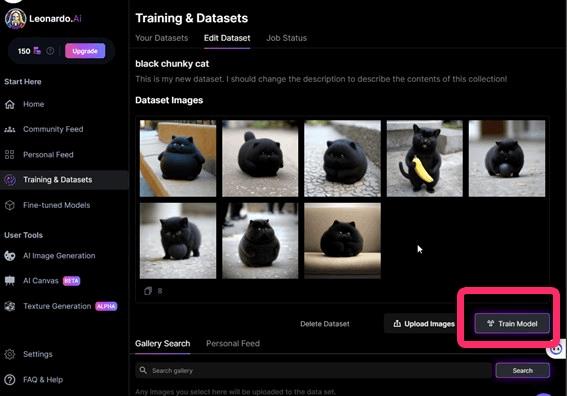
▲画像ファイルすべてアップロードしたら、Train Modelをクリックします。
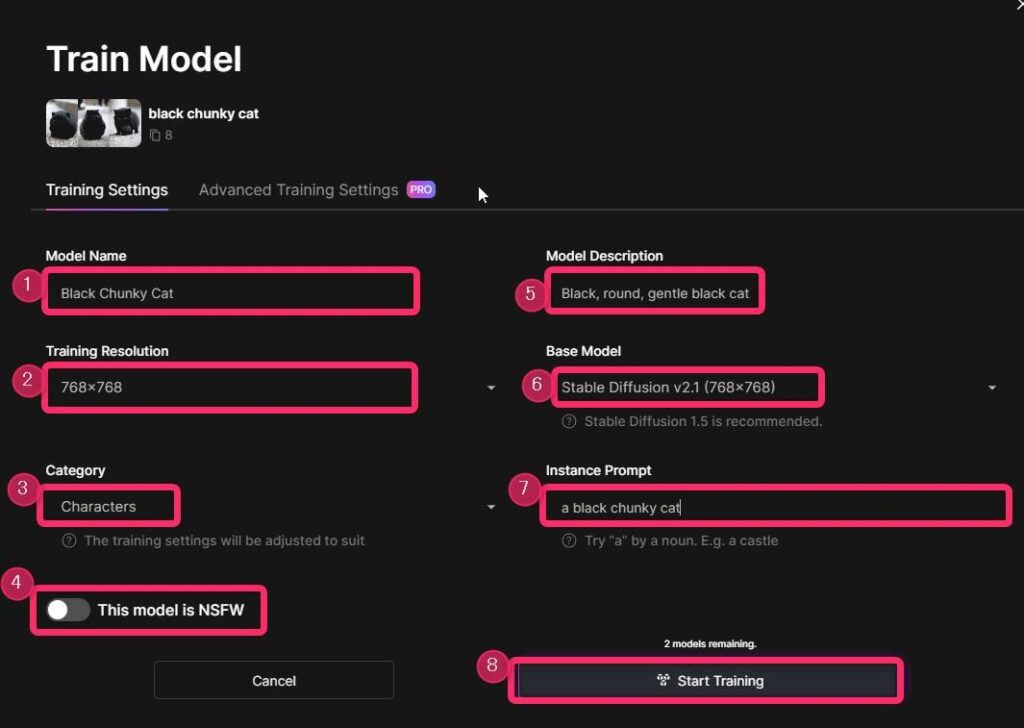
▲Train Modelの設定をします。
- Model Name:モデルの名前を決めます。
- Train Resolution:解像度
- Category:カテゴリーを選びます。「写真」「イラスト」などの中から適切なものを選びましょう。
- NSFW:NSFWに対応するモデルの場合は、有効にしましょう。
- Model Description:モデルの説明文章です。プロンプトや画像には影響しません。他の人がモデルを使用するときにどんなモデルかがわかるように説明文をかくことができます。
- Base Model:Stable Diffusion1.5かStable Diffusion2.1のどちらかを選ぶことができます。
- Instance Prompt:モデルのトリガーワードです。ここで設定したワードを使うことでモデルが機能します。
以上すべて設定したら図中⑧の「Start Training」をクリックすると、ファインチューニングが始まります。
じょじおInstance Promptは、画像生成の際にプロンプトに必ず含めることになる、とても重要なワードです。
他の汎用的な言葉を使うのを避けてオリジナリティのある言葉にしましょう。
わんこたとえばInstance Promptに「1girl」と設定してしまうと、1girlはプロンプトでよく使う言葉だから区別がつかなくなってしまって使いづらくなるよ。
モデルの学習時間は?
Start Trainingをクリックするとモデルの学習が始まります。
学習時間は少し時間がかかります。筆者の体感ではおよそ10分~30分程度かなと思います。
サーバーの状況によっては1時間程度かかることもあるようです。
学習作業はクラウドサーバー上で行われるので、画面を閉じたりPCの電源を閉じたりしても問題ありません。
一度画面を離れたあと、再び状況を確認する場合は、Training & Datasetsから確認できます。
3.自作モデルでAI画像生成する方法
じょじおさて、自作モデルができたら画像を生成してみましょう!
①自作モデルを選択します。
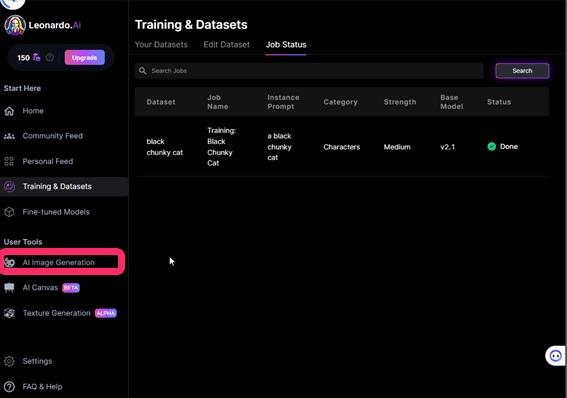
▲画像生成は、左側メニューの「AI Image Generation」から行います。
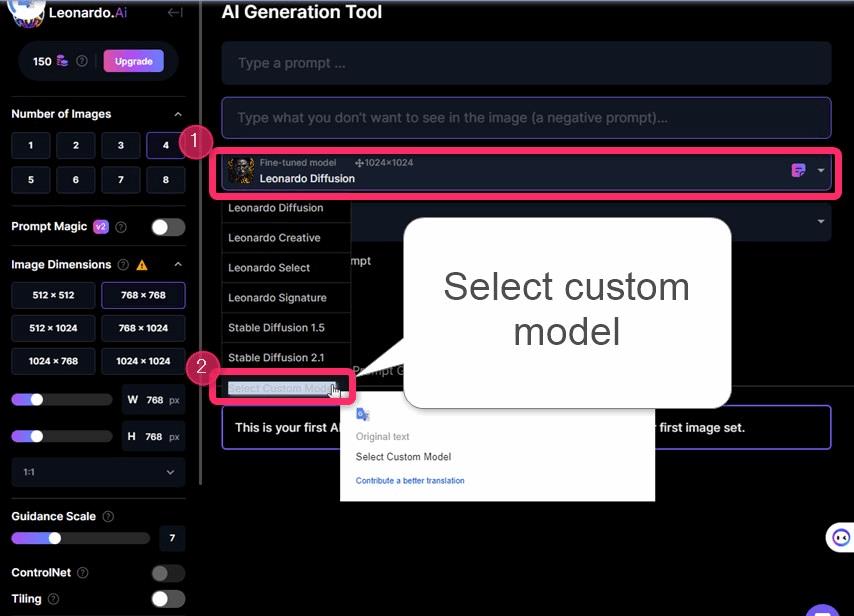
▲Finetuned modelのリストボックスから、Select custom modelをクリックします。
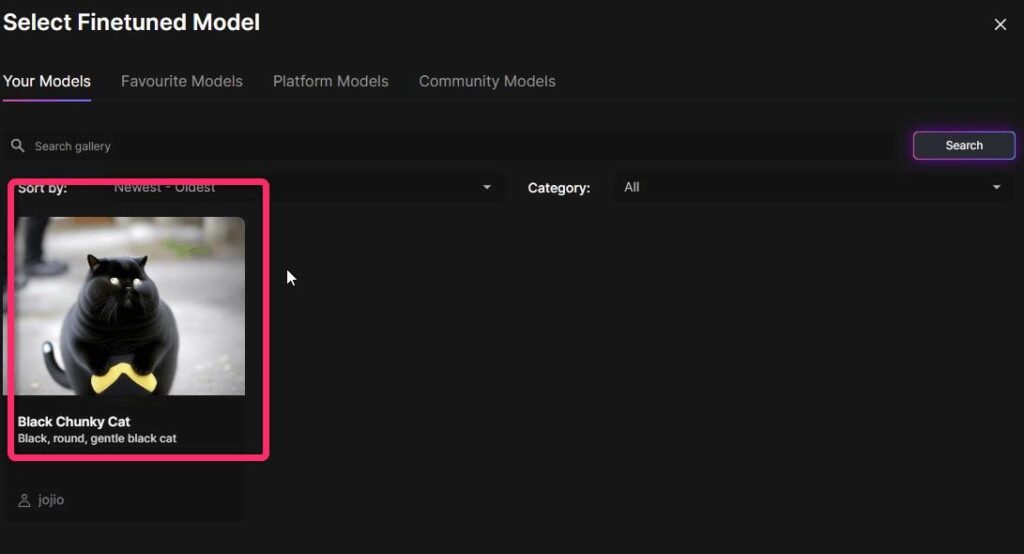
▲先ほど作成したモデルが表示されるのでモデルを選択して「view」をクリックします。
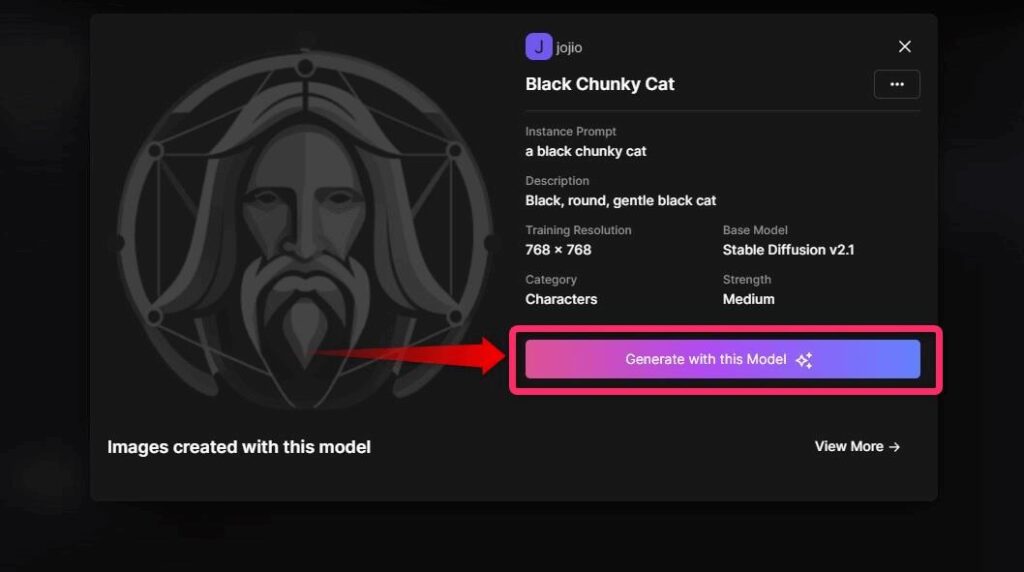
▲Generation with this modelをクリックします。
②プロンプトを入力して画像を生成します。
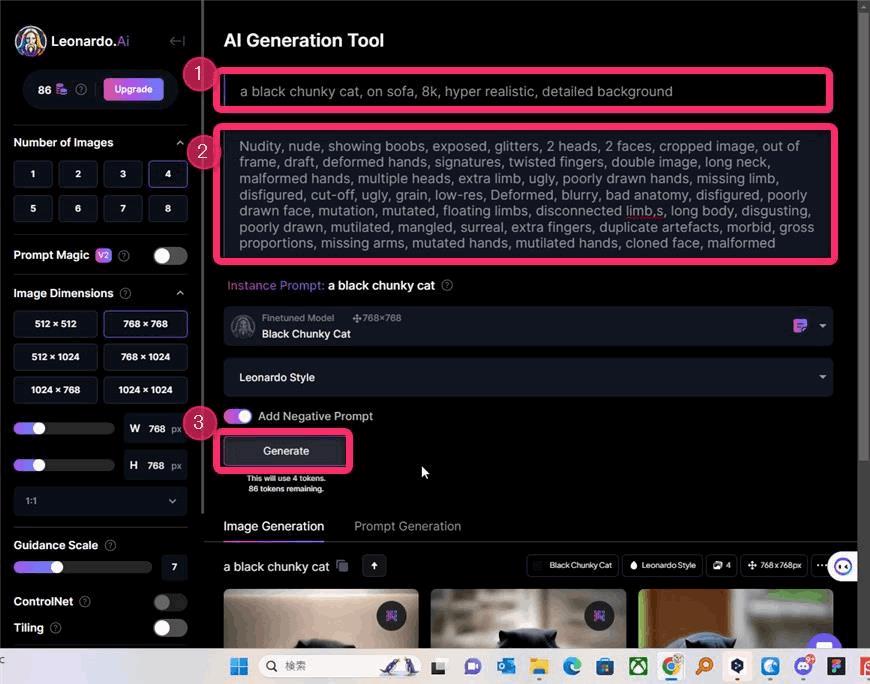
▲あとは通常通り下記のように画像を生成します。
- ①にプロンプトを入力します。
- ②にネガティブプロンプトを入力します。
- ③Generateで画像を生成します。
Instance Prompt(インスタンスプロンプト)をプロンプトに含めること!!
カスタムモデルを使った画像生成で重要なことは、Instance Prompt(インスタンスプロンプト)をプロンプトに含めることです。
インスタンスプロンプトを含めないと、カスタムモデルが効力を発揮しません。
Stable DiffusionのRoLaやLyCORISファイルを使ったことのある方であれば、トリガーワードといえばご理解いただけるでしょう。
③アップスケールします。
じょじお一回の画像生成では、綺麗な画像は生成できません。
生成した画像はアップスケールすることできれいな画像になります。
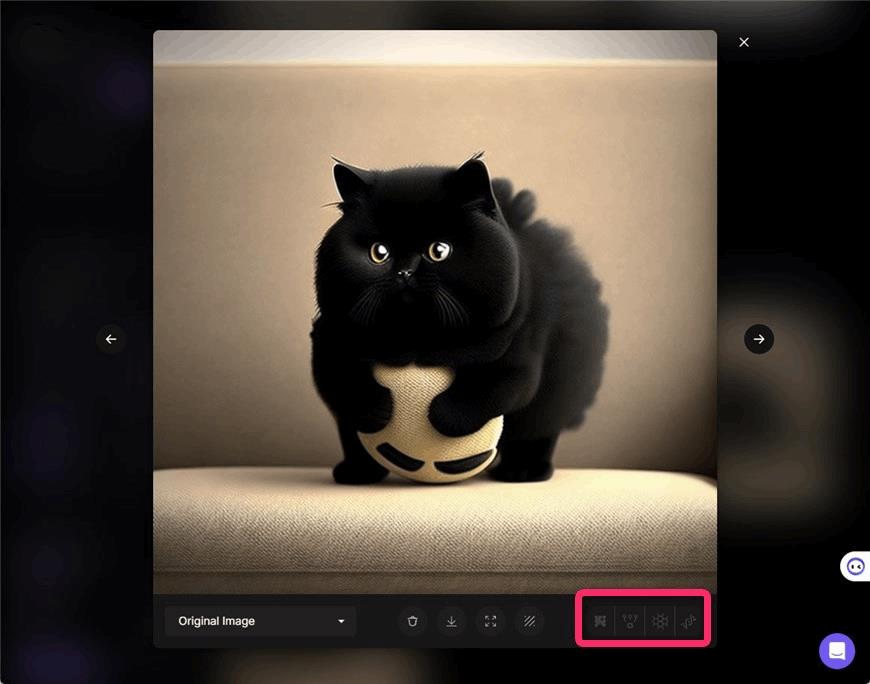
▲画像をアップスケールするには、生成された画像をクリックすると上図のような画像詳細画面がひらきますので、右下の4つのアップスケールボタンから好きなアップスケールアルゴリズムを選択します。
4つのアップスケールアルゴリズムは、実写系の画像に適しているもの、アニメ系に適しているものなど様々です。
私もよくわかっていないので、色々試してみてください。
すべてのアップスケールを試すこともできます。
1回のアップスケールに、5クレジット(5トークン)が必要です。

▲アップスケールをクリックするとアップスケールアイコンがロード中のアイコンに変化します。ロードが終わるまで数秒まちましょう。
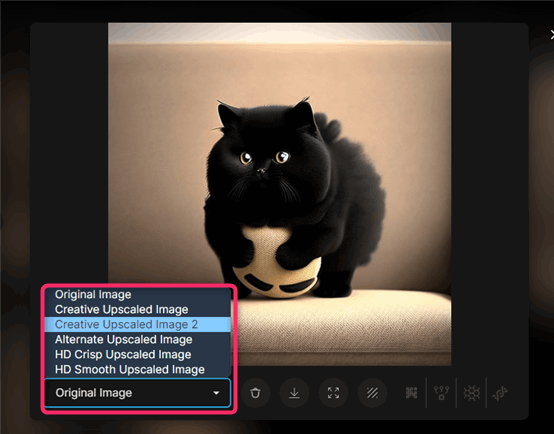
▲ロード中のアイコンが消えたらアップスケールは完了です。アップスケール後の画像を確認するには、左下の「Original Image」というリストボックスをクリックして、〇〇Upscaled Imageを選択します。〇〇はアップスケールアルゴリズムの名前です。
Leonardo.Aiのファインチューニングの注意点
Leonardo.AIで学習に使用する画像データは、著作権などの問題に注意して自己責任で行ってください!
私は今回、Midjourneyで生成した画像を、学習データとして使用しました。
トレーニングがうまくいかない場合は?
トレーニングがうまくいかない場合は、
- 画像ファイルを増やしてみる
- 画像ファイルの品質を確認してみる
- 画像ファイルのバリエーションを変えてみる。
以上を確認して、再トレーニングをしてみるのがいいでしょう。
ただし、無料ユーザーの場合、モデルの学習は再トレーニングを含めて月に2回までなので注意してくださいね。
じょじお困ったら下記のドキュメントの確認と、Leonardo.aiのDiscordも確認してみてね!
Leonardo.aiヘルプ&ドキュメント
Leonardo.AiのDiscord
↑のトップページに専用Discordサーバーへの案内があります。
まとめ
以上、Leonardo.ai でカスタムモデルを作成する方法について紹介しました!
じょじお最後まで読んでくださってありがとうございます!
この記事がお役に立てましたら、シェアボタンからシェアしていただけたら嬉しいです!

【おすすめUdemy講座】Midjourney始め方から応用まで網羅!【完全版】
【おすすめUdemy講座】ジェネレーティブAI(生成AI)入門【ChatGPT/Midjourney】 -プロンプトエンジニアリングが開く未来-
コメント